下载720云的全景图
最近经常需要查看720上的一些全景图。后来我就想把全景图下载下来,就方便很多。一开始自己也摸索了一阵子,用浏览器的开发者模式抓包分析了一阵子。但好像有点摸不着头脑,哈哈哈哈哈。后来搜了一下发现了这篇文章。文章使用了多个软件来批量下载合并图片并得到全景图。根据这篇博客,我优化了一部分工作流。所以下面是对整个过程的记录。
抓包分析
在Chrome浏览器中按F12并切换到网络(Network)选项卡。可以发现会加载一些形如l?_?_0?_0?.jpg的图片。这些有规律的图片就能构成整个全景图。
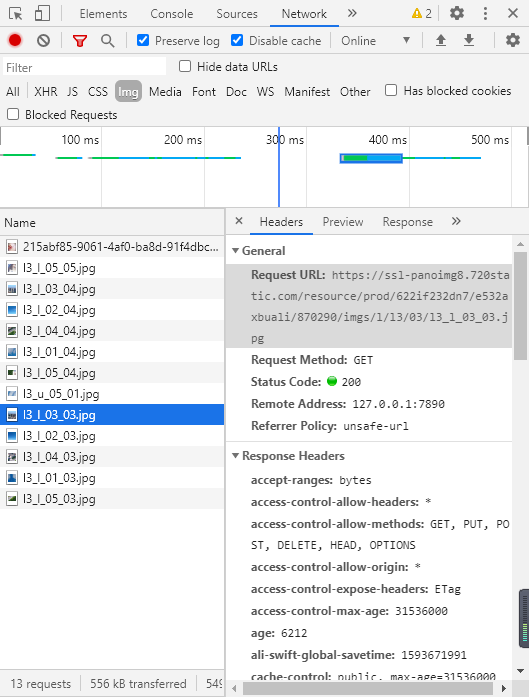
文件名的规律
关键的问题在于如何找出这些文件的规律,从而推出一个全景图所有的图片,并将其爬取下来。这需要非常强的观察能力,也是我弄不明白的地方。在查看了上述文章后明白。图片文件名的命名规律如下:
l[1-3]_[f, b, l, r, u, d]_0[1-5]_0[1-5].jpg
所以我们很快就可以使用3层循环构造所有的排列组合:
# 构造6个面
for faceCode in ('b','d','f','l','r','u'):
# 似乎有3层清晰度,这里只取第三层
for layerCode in range(3,4):
# 每层里面一般又有5个子文件夹(表示矩阵的行)
for subFold in range(1,6):
# 每个子文件夹里面又有5个图片(表示矩阵的列)
for picCode in range(1,6):
pathStr = "{}/l{}/0{}/l{}_{}_0{}_0{}.jpg".format(faceCode, layerCode, subFold, layerCode, faceCode, subFold, picCode)
urlsList.append(urlHead + pathStr)
爬取图片
我们可以进一步使用python抓取图片,省去手工使用批量下载工具的麻烦。可以使用requests库。这个库的作用看名字可以看的出来。其中有get方法。只需要构造请求,就能得到图片。
这里我还踩了个坑。我发现,如果是直接访问则会返回403错误。初步判断可能是Header不一样。服务会对Header做一些解析判断来防止爬取。于是在python里我们也要构造相同的Header。具体的请求头可以从Chrome开发者选项中复制。其中有个referer字段是要替换成原始的url的。
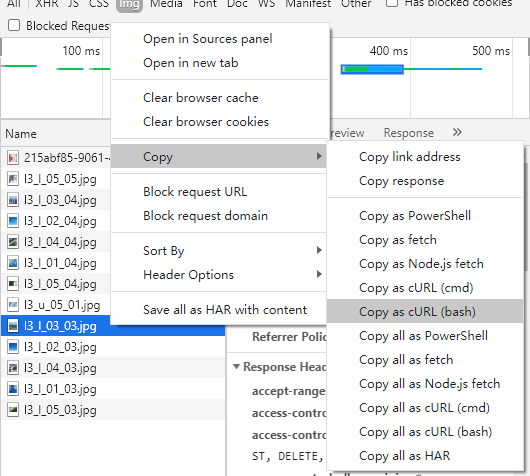
然后改为python的字典类型即可:
headers = {
'Content-Type': 'image/jpeg',
'authority': 'ssl-panoimg6.720static.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'origin': 'https://720yun.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'dnt': '1',
'accept': 'image/webp,image/apng,image/*,*/*;q=0.8',
'sec-fetch-site': 'cross-site',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'image',
'referer': originUrl,
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7'
}
接下来使用一个循环即可完成将遍历得到的所有url图片请求下载的操作:
for i in range(len(urlsList)):
url = urlsList[i]
print('\r'*8 + "{}/{}".format(i+1, len(urlsList)), end='')
try:
r = requests.get(url=url, headers=headers)
except Exception as e:
print('get 出了点问题:{}'.format(e))
if r.status_code == 200:
with open('img/' + url.split('/')[-1], 'wb') as f:
f.write(r.content)
print("\n下载完成")
图片的拼接处理
当我看到 f, b, l, r, u, d 这些字母的时候。我感觉挺熟悉的。我知道它是前后左右上下的意思。但我不太清楚他们是怎么安排在全景图上的。因为以前对全景图接触过,一般是一张宽高比为2:1的图像。这个图像在查看的时候会被贴到一个球体上。因而可以360度地查看。所以一开始我还画了这样一张图。

但是后来我才发现这些字母描述的是正方体的6个面。难怪我觉得那么熟悉,原来和魔方公式里的表示一毛一样!
所以720云显示所需的是正方体投影的图片。而不是球体投影。而720云又将每个正方体贴图分割成了5X5=25张图片。这也是文件名最后两个数字的含义。而文件名开头的l?表示清晰度。1最小,3最大(可能还有更大的,但我没遇见过)。因此如果要下载最高清的图片直接下载l3开头的图片即可。
一个简单的拼接图片,我也不想再去下工具了。所以直接用python的pillow库写了图片拼接的程序:
# together.py
import PIL
from PIL import Image
def 横向拼接(imagesList):
# 检查图像高度是否一致
# 方法是生成高度列表并和另一个内部元素完全是和第一个一样的列表相比较
heights = list(map(lambda image: image.size[1], imagesList))
isHeightEqual = [heights[0] for x in range(len(imagesList))] == heights
if not isHeightEqual:
raise Exception('高度不匹配')
widths = tuple(map(lambda image: image.size[0], imagesList))
# 新建画布
imageBig = Image.new(mode='RGB', size = (sum(widths), heights[0]))
# 开始逐个粘贴
for i in range(len(imagesList)):
image = imagesList[i]
imageBig.paste(image, (sum(widths[:i]), 0, sum(widths[:i+1]), image.size[1]))
return imageBig
def 竖向拼接(imagesList):
# 检查图像宽度是否一致
widths = list(map(lambda image: image.size[0], imagesList))
isWidthsEqual = [widths[0] for x in range(len(imagesList))] == widths
if not isWidthsEqual:
raise Exception('宽度不匹配')
heights = tuple(map(lambda image: image.size[1], imagesList))
# 新建画布
imageBig = Image.new( mode='RGB', size = (widths[0], sum(heights)) )
# 开始逐个粘贴
for i in range(len(imagesList)):
image = imagesList[i]
imageBig.paste(image, (0, sum(heights[:i]), image.size[0], sum(heights[:i+1])))
return imageBig
# matrixD 矩阵维度元组
# flatImagesList 用于拼接的扁平化的图像列表
def 矩阵拼接(matrixD, flatImagesList):
if matrixD[0] * matrixD[1] != len(flatImagesList):
raise Exception("给定矩阵尺寸与得到的图像个数不符。")
imagesLines = list()
# 拼接所有行
for lineIndex in range(matrixD[0]):
imagesLines.append(横向拼接(flatImagesList[lineIndex * matrixD[1] : (lineIndex + 1) * matrixD[1]]))
# 竖向拼接
return 竖向拼接(imagesLines)
def 拼接所有(path):
import os
import math
fileNames = os.listdir(path)
# 按文件名整理各个面的文件名到一个字典中
sixFaceDict = {}
for fileName in fileNames:
sixFaceDict[fileName[3]] = sixFaceDict.get(fileName[3], list())
sixFaceDict[fileName[3]].append(path + fileName)
# 按路径全部替换成image
for face in sixFaceDict:
for i in range(len(sixFaceDict[face])):
sixFaceDict[face][i] = Image.open(sixFaceDict[face][i])
# 拼接
for face in sixFaceDict:
linesNum = int(math.sqrt(len(sixFaceDict[face])))
sixFaceDict[face] = 矩阵拼接((linesNum, linesNum), sixFaceDict[face])
# 输出宽度
print("pano width should be: {}".format(
sixFaceDict['f'].size[0] +
sixFaceDict['b'].size[0] +
sixFaceDict['l'].size[0] +
sixFaceDict['r'].size[0]
))
# 保存
for face in sixFaceDict:
sixFaceDict[face].save('result/'+ face + '.jpg')
if __name__ == '__main__':
拼接所有( 'img/')
上面提到的另外的爬取完整代码如下:
# dimg.py
# origin url e.g. https://720yun.com/t/3922fmO5jyg?scene_id=640863
# request url e.g. https://ssl-panoimg6.720static.com/resource/prod/622if232dn7/e532axbuali/521330/imgs/
originUrl = input('Please input origin url: ')
urlHead = input('Please input request url: ')
urlsList = list()
# 构造6个面
for faceCode in ('b','d','f','l','r','u'):
# 似乎有3层清晰度,这里只取第三层
for layerCode in range(3,4):
# 每层里面一般又有5个子文件夹(表示矩阵的行)
for subFold in range(1,6):
# 每个子文件夹里面又有5个图片(表示矩阵的列)
for picCode in range(1,6):
pathStr = "{}/l{}/0{}/l{}_{}_0{}_0{}.jpg".format(faceCode, layerCode, subFold, layerCode, faceCode, subFold, picCode)
urlsList.append(urlHead + pathStr)
# 开始请求
import requests
headers = {
'Content-Type': 'image/jpeg',
'authority': 'ssl-panoimg6.720static.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'origin': 'https://720yun.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'dnt': '1',
'accept': 'image/webp,image/apng,image/*,*/*;q=0.8',
'sec-fetch-site': 'cross-site',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'image',
'referer': originUrl,
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7'
}
for i in range(len(urlsList)):
url = urlsList[i]
print('\r'*8 + "{}/{}".format(i+1, len(urlsList)), end='')
try:
r = requests.get(url=url, headers=headers)
except Exception as e:
print('get 出了点问题:{}'.format(e))
if r.status_code == 200:
with open('img/' + url.split('/')[-1], 'wb') as f:
f.write(r.content)
print("\n下载完成")
import together
together.拼接所有('img/')
运行完后,可在result目录下得到6个面的图像。接下来就是要将他们转换成常见的2:1球面投影图了。
投影图转换
网上有很多工具可以进行这种转换。那么我还是以pano2vr为例来进行说明。
首先是点击选择输入,分别选择6个面:
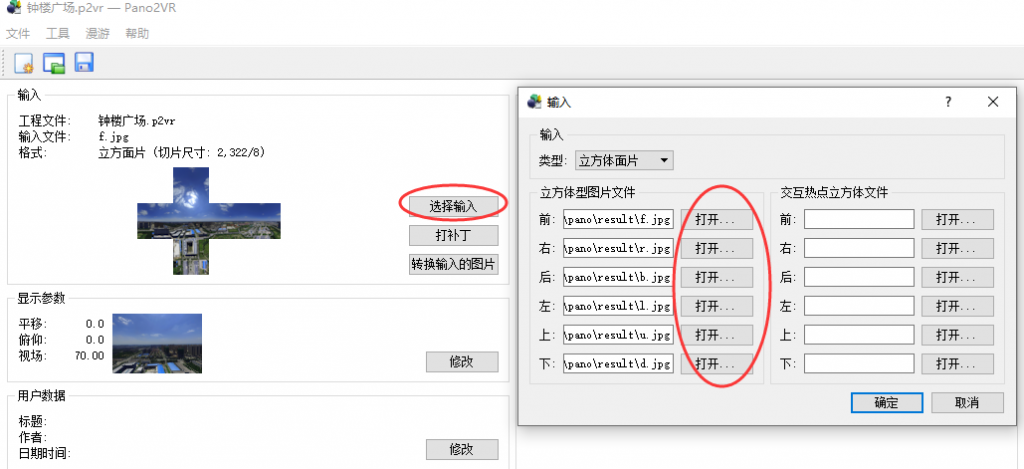
点击显示参数的修改可以预览。
最后在新输出格式中选择变形——添加。添加一个类似于配置文件的东西。可以注意到我下面已经有了一个。如果没有,一开始就要添加一个。因为这个软件的设计是考虑可以一次批量输出多种格式的。
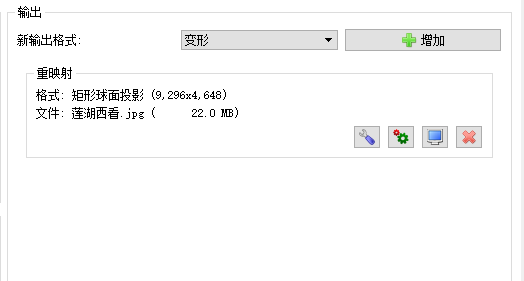
随后进行设置。这里要说明的是图片尺寸是上下左右(udlr)的宽度的和。因为观察立方体展开图可知上下左右最后会被线性变换到球面投影图的中间部分,那是几乎没有变形的部分。所以取它们的宽度相加就是原始尺寸了。在我的合并程序里已经有计算代码,并将结果输出到终端了,搬过来即可。
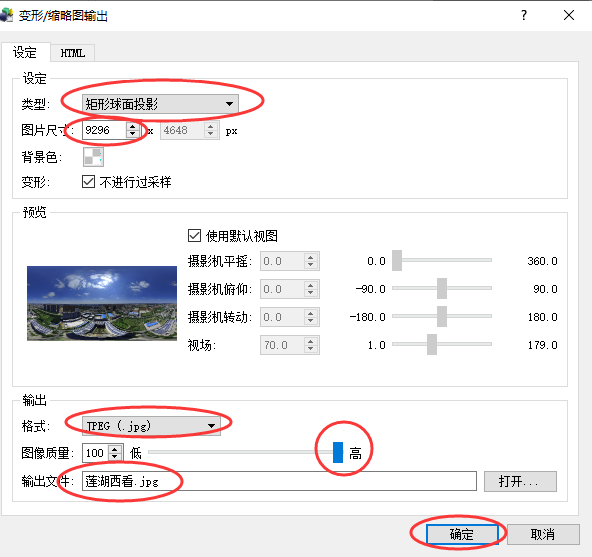
点击确定就可以输出一张完整的全景图啦^^。
软件无法识别全景图的问题
上面这些步骤完成,全景图就制作完成了。但你可能会发现使用QQ空间,微博发送的时候并不能识别为全景图,还是普通的图片。这是因为它们会读取图片中的Exif(文件元数据)。元数据就是描述数据的数据。如果照相机不是全景相机,那么只会识别为普通的照片。没有全景功能。好在有软件可以添加虚假的全景相机拍摄信息。进而能让软件知道这是一个全景图。
使用 Exif-Fixer,添加元数据即可。
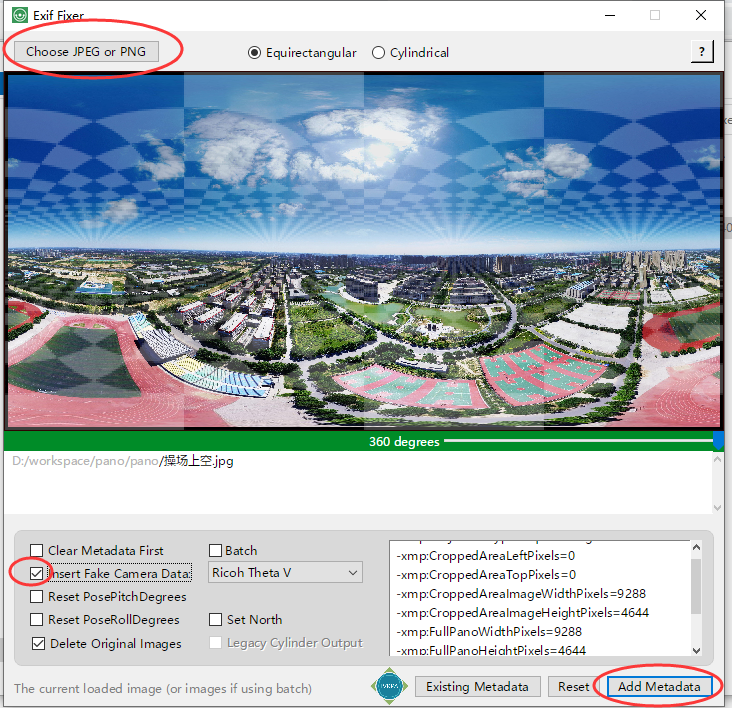
按步骤添加,其实我选择了Insta 360 One这个全景相机
大功告成
好久没写博客了。最近在做一个项目,要建模。经常要参考全景图。工作量还挺大的,又正好碰到了全景图下载的问题,折腾了半天。特地跑来记录一下,嘿嘿~