谈话类人声后期处理的工作流
我的人声处理工作流(谈话类,非唱歌)。就两步超好用。AU效果组—降噪…。如图一。这会比效果中的那个降噪(处理)…会更方便而且更有效。一是降噪效果比捕捉样本后降噪好,二是对声音的改变也会比自己手动选样本要少。
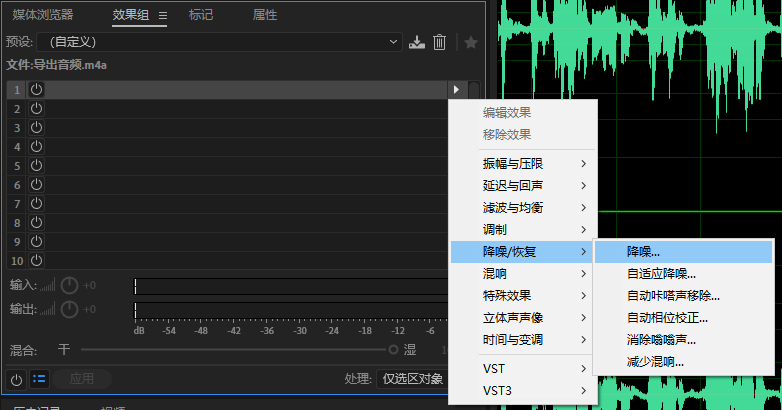
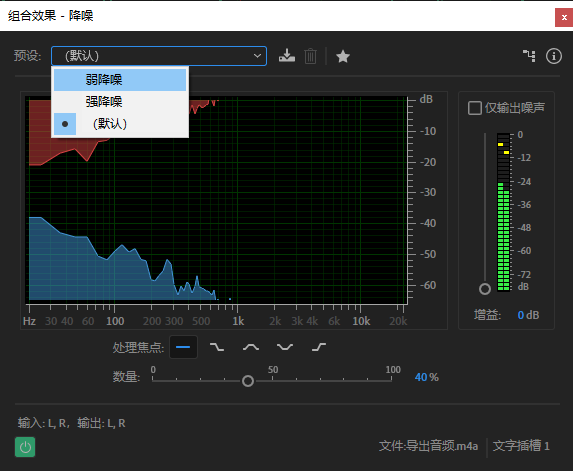
打开以后播放,根据听到的效果选择合适的预设(预设只调整了下面数量这个滑块,弱强默认分别代表低高中)。见图二。处理焦点可选择着重低频(因为噪音一般集中在低频)但选择全频段也无伤大雅。然后应用效果组(这是为了方便下一步查看处理后的不说话时候的噪音的电平)
然后就可以祭出大杀器。效果组—振幅与压限—动态(图三)。在该面板中可以完成动态范围相关的处理。预设选择噪声门。就会发现自动门勾选上了并且调整好了参数。该功能主要是对于低于阈值的区段进行静音处理。这样可以很好地屏蔽一些处理不干净的噪音(主要是口水声还有一些杂音)。
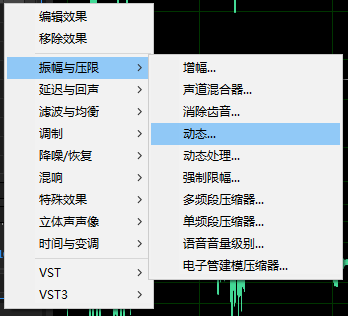
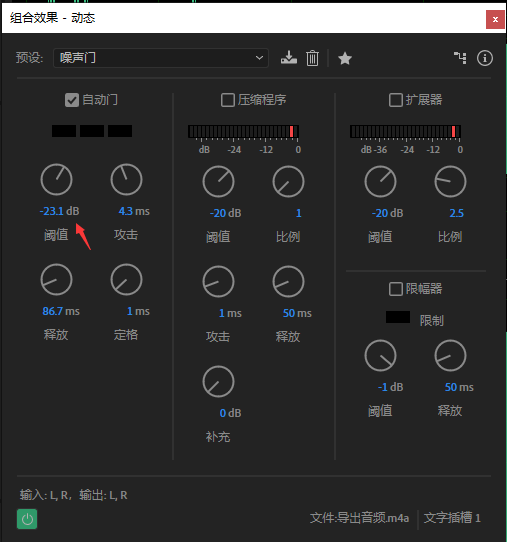
选择噪声门预设主要是用于继承其参数。默认的参数可以很好地实现自动静音了,一般不需要修改。要改的只是阈值。阈值我们只要在波形视图中找到不说话的部分。
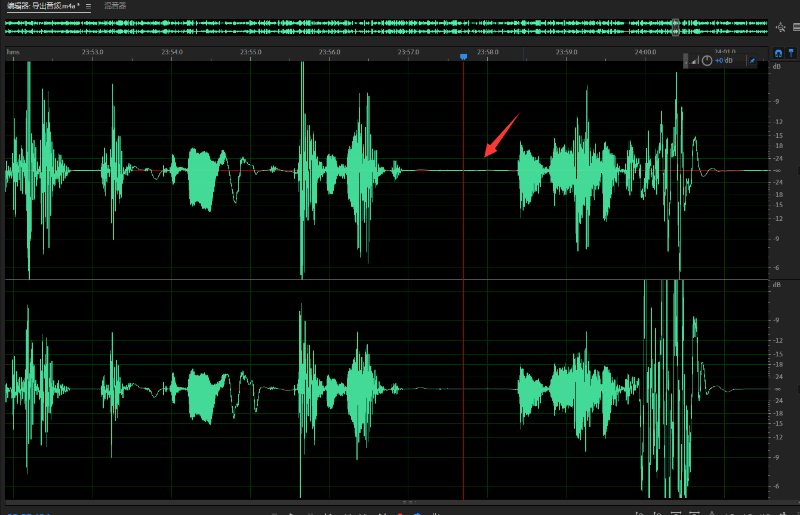
在其上滚动滚轮水平放大。在右侧电平刻度上滚动滚轮竖向放大。读出可以很好地包络大部分振幅峰值的电平值。这里是-52db。可以多找几个地方取平均值表情 注意那些像塔一样尖尖的凸出来的鹤立鸡群的我们不要包进去,否则处理就会影响到正常说话导致说话听起来一卡一卡。
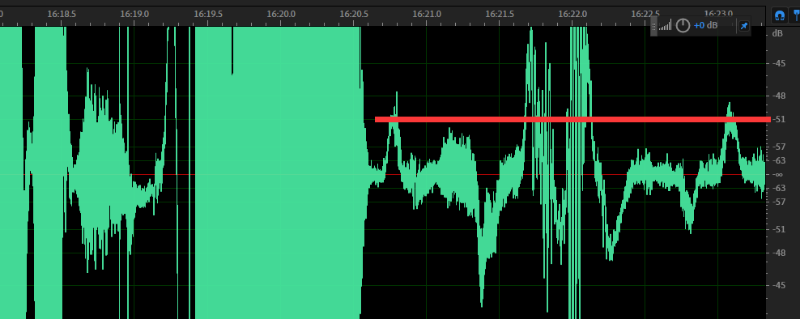
然后我们讲这个值填入噪声门的阈值中。然后空格键播放,就会发现在说话之间的停顿就会非常干净。可以根据听到的效果上下浮动这个阈值。
最后就是进行压缩。将尖锐的突出的部分压低,并提升人声的大小,虽然降低了动态范围,但是却提升了整体响度,人声听起来声音也会更响亮。
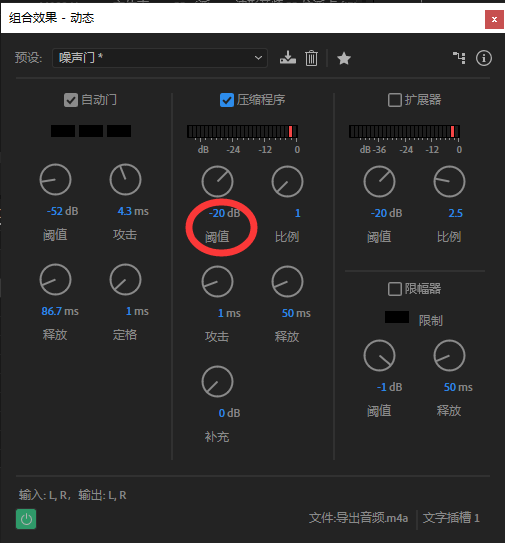
同样是在动态中勾选压缩程序来启用压缩。对于阈值,我们同样需要根据音频波形来判断。这里取讲话部分的稳定电平再降2db。也就是-20db。
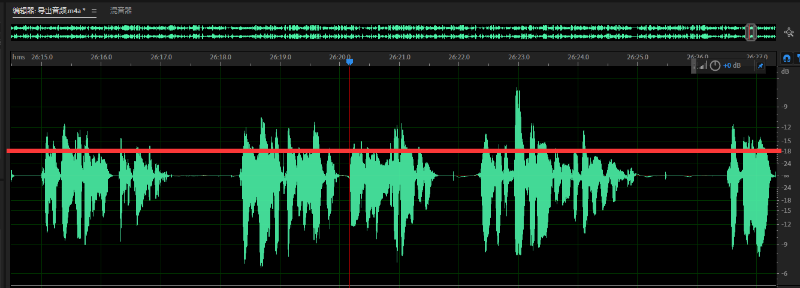
右边的比例参数表示要压低多少倍。这个值一般设置为4比较合适。但由于我这个音频中键盘打字声很突出。所以就使用8倍压缩。
Attack启动时间。一般来说,大约8~10ms比较自然。既不会压缩启动过快导致音头冲不上去也不会太慢启动没来得及压就过了这个区段了。release释放时间大约设置为300ms。释放时间快会提前放出音尾,声音更有亲切感。释放时间慢会压到音量不大的地方。
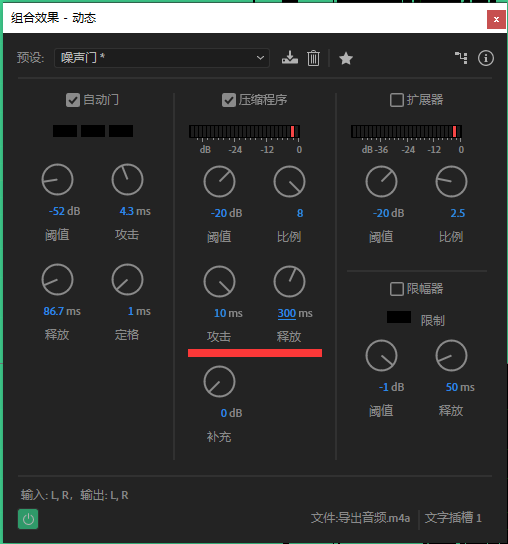
而最后一个参数,补充/增益,则是把压缩过后的音频再拉起来补偿一个压缩后损失的音量。这个值可以播放以后看着下面的电平表,将值拉大。调整为峰值是将爆未爆的状态。峰值接近0db左右,偶尔可以爆。(如果增益拉到顶还是很小声的话,这就是前期录音电平太小了,没推起来。即便加增幅强拉起来也会获得一个非常低信噪比的音频。建议重录。)

对于数字音频,过爆会导致失真。这是不能接受的。因此打开限幅器。将超过-1db的部分直接压小(不设置为0db,是因为留一点冗余,偏于安全)。释放时间不宜过长否则影响到未超限的部分。这里设置为10ms。
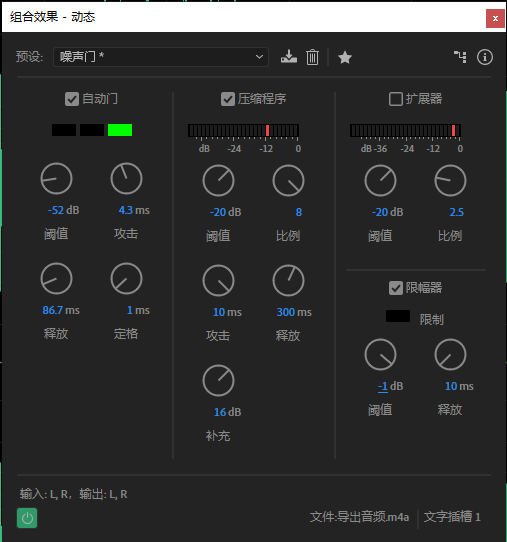
关闭窗口。对音频进行剪切修改等操作。满意后应用效果就可以导出了!
小结:我们先使用了降噪效果来除去在前期无法避免的噪声。而后使用动态来调节音频的动态范围使人声更易听清,不会忽大忽小。并将整体的响度提升到一个合适的大小(响度使用lufs衡量,可在振幅统计面板中查看)。这是基本的处理。对于声音的润色,如果使用立体声录制(XY或M/S),已经能获得比较宽广的声场。基本上不需要处理。如果是单声道录制,可以考虑加些模拟立体声的效果。